전체적인 개념을 설명하고 다음 글 부터 한 부분씩 자세히 볼 것
What is Kafka?
카프카란 데이터를 다루기 위한 미들웨어다.

Kafka 데이터 모델, 저장 소비 방식
Topic, Partition

- 카프카는 Pub/Sub 모델(발행 구독 모델)을 사용한다.
- Pub/Sub 이란 메세지 혹은 데이터를 제공하는 Publisher와 메세지 혹은 데이터를 소비하는 Consumer가 존재하여 데이터를 주고 받는 모델이다.
- 카프카는 Publisher가 제공한 데이터를 가지고 있고, Consumer는 카프카에서 데이터를 직접 가져오는 방식이다.
- Consumer가 직접 가져올 때의 이점
- 다양한 Consumer를 고려하지 않아도 된다. → Consumer가 다양하고, 카프카에서 데이터를 직접 보내주는 상황이라면 각 Consumer를 고려해서 데이터를 변환해야 했을 것
- Consumer가 처리가 가능할 때 가져오기 때문에 Consumer가 데이터를 처리할 수 있는데 대기해야할 일이 없다.
- Consumer가 직접 가져올 때의 이점
- 카프카는 Publisher가 제공한 데이터를 가지고 있고, Consumer는 카프카에서 데이터를 직접 가져오는 방식이다.
- Pub/Sub 이란 메세지 혹은 데이터를 제공하는 Publisher와 메세지 혹은 데이터를 소비하는 Consumer가 존재하여 데이터를 주고 받는 모델이다.
- Publisher와 Consumer는 Topic이라는 것을 통해 데이터를 구분한다.
- Topic으로 데이터를 구분해서 각 모듈들은 필요한 데이터를 쓰고, 읽는 주제를 정할 수 있다.
- 각 Topic에는 Partition이라는 단위로 데이터를 분산 저장한다.
- 이떄 저장하는 방식은 라운드-로빈 방식이다 → 데이터가 순차적으로 저장되는 것을 보장하지 못함(운영체제의 라운드 로빈과 약간의 차이가 존재?) → 파티션이 4개 존재할떄 0->1->2→3 순서로 저장되지 않음
- 분산 저장하기 떄문에 빠른 저장속도를 지원한다. 하지만, 파티션의 개수를 잘 정하는 것이 중요하다.(일반적으로 파티션 - 컨슈머 1:1 관계 혹은 파티션이 2배수 인게 제일 효과적이라고 함)
- 파티션안에 저장된 메세지들은 파티션안에서는 순서가 보장된다.(파티션이 하나의 Queue라고 생각하면 된다.), 하지만 컨슈머가 여러 파티션에서 메세지를 가져온다면 각 메세지의 시간 순서는 모른다.
- Consumer는 가져온 데이터(offset)에 Commit을 하고, 다음에 가져올 데이터는 Commit을 한 offset이후의 데이터를 가져온다.
- Publisher는 단지 Topic에 데이터를 보낼뿐, 어떤 파티션에 저장할지는 몰라도 됨, → 로컬에서 확인해본 결과 Kafka에서 라운드-로빈으로 적절히 분배를 하고있음(50만건을 Pub했고, 파티션 4개)
- 각 컨슈머들은 컨슈머 그룹으로 묶일 수 있으며 컨슈머 그룹에서 파티션을 적절히 분배해서 읽음
- consumer one: 128212 124491 0 0
consumer two: 0 0 127330 119967
- consumer one: 128212 124491 0 0
@Service
public class ConsumerStatistics {
public int[] one={0,0,0,0};
public int[] two={0,0,0,0};
public void insertOne(int partition){
one[partition]++;
}
public void insertTwo(int partition){
two[partition]++;
}
public void printResult(){
System.out.println("consumer one: "+one[0]+" "+one[1]+" "+one[2]+" "+one[3]+" ");
System.out.println("consumer two: "+two[0]+" "+two[1]+" "+two[2]+" "+two[3]+" ");
}
}
--------------------------
@KafkaListener(topics = "myKafka",groupId = "study")
public void consume(@Payload String msg, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) throws IOException {
System.out.println("consumer 1: "+msg+", partition: "+partition);
consumerStatistics.insertOne(partition);
}
-------------------------
@KafkaListener(topics = "myKafka",groupId = "study")
public void consume(@Payload String msg, @Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition) throws IOException {
System.out.println("consumer 2: "+msg+", partition: "+partition);
consumerStatistics.insertTwo(partition);
}
Cluster, Replication
bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 4 --topic myKafka카프카는 데이터를 저장한 곳이기 떄문에 장애가 발생했을 시 데이터를 지킬 수 있는 방법이 필요하다.
그래서 카프카는 Cluster구조로 데이터를 저장할 수 있는 '브로커'라는 단위로 나눠져 있다.
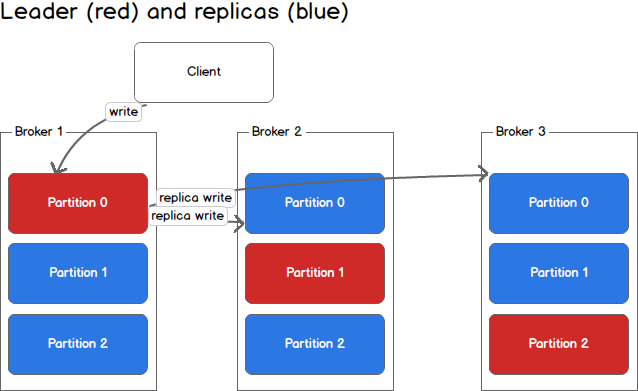
(위에서 leader replicas라고 해놨는데 Kafka에서는 leader, follower라고 하는게 맞다고 한다.)
위 명령어의 --replication-factor 1 부분이 토픽을 몇개의 Broker에 분산 저장할지 지정하는 것 → 토픽별로 따로 설정이가능(중요 데이터는 3, 안 중요한 것은 1)
- 브로커에는 위에서 설명한 파티션들이 저장 되는데, 토픽을 구성하는 파티션들이 여러 브로커에 분산 저장되는 것이다.
- 동일한 파티션이 브로커에 나눠져 있을 떄 이 파티션들(Broker1 - Partition 0, Broker2 - Partition 0, Broker3 - Partition 0)을 ISR(In Sync Replicas)라고 한다. → 분산된 파티션들을 그룹화 한것
- 리더 파티션은 읽고, 쓰기 모두 가능하고 팔로워는 읽기만 가능하다.
- 모든 브로커가 Down 됐을때 대처 방안 2가지
- 가장 최근 까지 Leader였던 파티션이 살아나는 것을 기다린다 → 최대한 많은 데이터를 가지고 있을 것 → 하지만 Leader가 있던 브로커가 언제 살아날지 모르는 문제가 있음
- 가장 빠르게 Up된 브로커에 있던 파티션이 Leader가 된다 → 빠른 장애 대응이 가능하다. → 디폴트 설정으로서 데이터 유실의 문제가 있다.
Kafka 리밸런싱
카프카 파티션당 하나의 컨슈머만 붙을 수 있는데 이떄 컨슈머가 죽거나, 새로운 컨슈머가 생기거나, 파티션이 늘어날떄 컨슈머들에게 파티션을 새롭게 분배하는 것을 리밸런싱이라고 한다.(컨슈머 그룹 코디네이터라는것이 자동으로 해준다.)
ex) 컨슈머가 죽었을 때, 파티션 4개, 컨슈머 2개
→ 컨슈머 a는 파티션 1,2에붙고, 컨슈머b는 파티션 3,4에 붙은 상황에서 컨슈머b가 죽는다면
→ 자동으로 컨슈머a에 파티션 1,2,3,4가 붙는다.
ex2) 컨슈머가 중간에 들어왔을 떄, 파티션 4개, 컨슈머 1개->2개
→ 컨슈머 a에 파티션 1,2,3,4가 붙었을 떄 컨슈머 b가 들어온다면
→ 컨슈머a에는 파티션 1,2 컨슈머b에는 파티션3,4가 붙는다.
ex3) 컨슈머 2개, 파티션 2개 → 파티션 4개로 늘어날떄
→ 컨슈머들은 각자 1개씩 추가로 파티션에 붙는다.
카프카에서 자동으로 리밸런싱을 지원해주지만, 리밸런싱을 하는 동안에는 어떤 컨슈머도 파티션에서 메세지를 읽어 올 수 없다.
→ Pod가 죽었을때한번 리밸런싱을 하고, Pod가 살아났을 떄 리밸런싱을 한다면 2차례 메세지를 읽지 못하는 시간이 생김
중간에 컨슈머가 죽었을 때
2021-07-09 15:30:09.858 INFO 39340 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Attempt to heartbeat failed since group is rebalancing
2021-07-09 15:30:09.858 INFO 39340 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-study-2, groupId=study] Attempt to heartbeat failed since group is rebalancing
2021-07-09 15:30:09.859 INFO 39340 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Revoke previously assigned partitions myKafka-2
2021-07-09 15:30:09.859 INFO 39340 --- [ntainer#1-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-study-2, groupId=study] Revoke previously assigned partitions myKafka-3
중간에 컨슈머가 들어왔을때
2021-07-09 15:26:42.616 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-study-1, groupId=study] (Re-)joining group
2021-07-09 15:26:42.623 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Successfully joined group with generation Generation{generationId=18, memberId='consumer-study-1-3bf9afd0-e5e3-40fe-b4a6-6f1a0d1b8206', protocol='range'}
2021-07-09 15:26:42.624 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Finished assignment for group at generation 18: {consumer-study-2-ca73af8e-073a-4e75-bfbb-b65f78590505=Assignment(partitions=[myKafka-3]), consumer-study-1-3bf9afd0-e5e3-40fe-b4a6-6f1a0d1b8206=Assignment(partitions=[myKafka-0, myKafka-1]), consumer-study-1-85fcb02f-c0e3-4544-8c0f-22a46c8b4351=Assignment(partitions=[myKafka-2])}
2021-07-09 15:26:42.629 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.AbstractCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Successfully synced group in generation Generation{generationId=18, memberId='consumer-study-1-3bf9afd0-e5e3-40fe-b4a6-6f1a0d1b8206', protocol='range'}
2021-07-09 15:26:42.630 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Notifying assignor about the new Assignment(partitions=[myKafka-0, myKafka-1])
2021-07-09 15:26:42.630 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Adding newly assigned partitions: myKafka-1, myKafka-0
2021-07-09 15:26:42.632 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Setting offset for partition myKafka-1 to the committed offset FetchPosition{offset=372062, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[10.102.40.200:9092 (id: 0 rack: null)], epoch=0}}
2021-07-09 15:26:42.633 INFO 39187 --- [ntainer#0-0-C-1] o.a.k.c.c.internals.ConsumerCoordinator : [Consumer clientId=consumer-study-1, groupId=study] Setting offset for partition myKafka-0 to the committed offset FetchPosition{offset=382457, offsetEpoch=Optional.empty, currentLeader=LeaderAndEpoch{leader=Optional[10.102.40.200:9092 (id: 0 rack: null)], epoch=0}}
관련 링크:
아피치 카프카 공식 문서: https://kafka.apache.org/documentation/#configuration
스프링 카프카 스타터 문서: https://docs.spring.io/spring-kafka/reference/html/#kafka-listener-annotation
'Kafka' 카테고리의 다른 글
| Kafka Cluster 구성 (0) | 2022.01.14 |
|---|---|
| Kafka auto commit (0) | 2021.11.23 |

