- 실행제어
- 동기화
이번글이 쓰레드의 마지막이면서 쓰레드의 가장 핵심적인 내용이다.
1. 실행제어

쓰레드는 실행시키고, 중단시키는일을 실행제어라고 한다.
쓰레드는 우리가 처리해야할 작업들을 병렬로 처리해야 할 때 사용하는데, 각 작업들의 실행을 중간에 중단시킨다던가, 아니면 중단 되었던 작업을 실행시키는것을 직접 제어해야 할 때가 있다. 이번에는 이렇게 직접 제어할 수 있는 쓰레드 메소드들을 알아보고 적당한 사용방법을 알아보겠다.
1-1 sleep
우선 쓰레드를 일시적으로 멈추는 sleep이 있다.
public class Main {
public static void main(String[] args) {
Thread thread=new Thread(()->{
for(int i=0;i<100;i++){
if(i%10==0){
try{
Thread.sleep(1000);
}catch (InterruptedException e){
System.out.println("interrupt");
}
}
System.out.println(i);
}
});
thread.start();
}
}위 코드는 0~99까지를 출력을하는데 10초 단위로 중간에 1초씩 쓰레드를 쉬게한다.
그런데 보면 try-catch문으로 감싼것을 볼 수 있다. 이유는 sleep으로 중단한 쓰레드가 다시 시작될때 InterruptedException이 발생하기 때문이다. 그래서 sleep은 항상 try-catch문으로 감싸주어야 한다.
public static native void sleep(long millis) throws InterruptedException;다음으로 위 코드는 자바 Thread클래스의 sleep의 부분이다. 여기서 한가지 눈여겨 봐야할것은 static이다.
알다싶이 static메소드는 클래스의 인스턴스들이 모두 공유한다. 그렇다는것은 sleep를 호출한 참조체가 아닌 다른 쓰레드가 영향을 받을 수 있다는것이다. 다르게 말하면 sleep은 현재 실행중인 쓰레드를 중지시키는것이다.
public class SleepTest {
public void test(){
Thread thread1=new Thread(()->{
for(int i=0;i<100;i++){
System.out.println("thread1");
}
System.out.println("thread1 종료");
});
Thread thread2=new Thread(()->{
for(int i=0;i<100;i++){
System.out.println("thread2");
}
System.out.println("thread2 종료");
});
thread1.start();
thread2.start();
for(int i=0;i<100;i++){
System.out.println("main");
if(i==0){
try{
thread1.sleep(2000);
}catch(InterruptedException e){}
}
}
System.out.println("main 종료");
}
}

위 코드에서 보면 중간에 thread1을 sleep시켰다. 하지만 종료순서는 main이 가장 마지막에 종료되었다. 만약 sleep이 호출한 쓰레드를 중지시키는것이라면 thread1이 2초간 중단 되기 때문에 가장 마지막에 종료되어야 하지만 그렇지 않기 때문에 main이 가장 마지막에 종료된것을 알 수 있다.
1-2 interrupt
다음으로는 쓰레드를 중단시킬 수 있는 2번째 방법인 interrupt이다. 위의 sleep은 현재 실행중인 쓰레드를 중단시키는 역할지지만 interrupt는 호출한 쓰레드를 중단시키는 역할을 한다.
public class Scheduling extends Thread{
public void run(){
while(!isInterrupted()){
System.out.println("test run!");
}
}
}
public class Main {
public static void main(String[] args) {
Scheduling scheduling=new Scheduling();
scheduling.start();
for(int i=0;i<1000;i++){
if(i==500){
scheduling.interrupt();
}
System.out.println(i);
}
}
}위코드는 쓰레드를 생성해서 test run!이라는 문구와 Main쓰레드에서 숫자를 찍다가 숫자가 500이 되었을때 다른 쓰레드를 중지시키는 코드이다. 실행을 해보면 500이후에는 test run!이라는 문구는 찍히지 않는것을 볼 수 있다.
참고로 interrupt는 쓰레드를 중지만 시킬뿐 종료시키지는 못한다.
1-3 yield
yield는 다른 쓰레드에세 자신의 실행시간은 넘겨주는 것이다. 예를들어 현재 실행중인 쓰레드의 실행시간이 1초라고 했을때 1초중 0.5초를 사용한뒤 yield를 사용하면 남은 0.5초를 다음 쓰레드로 넘겨준다.
public static native void yield();yield또한 static 메소드이다. 즉, 누가 호출을 하던간에 그냥 현재 실행중인 쓰레드가 양보를한다.
yield는 주로 쓰레드가 자신의 실행 차례가 왔지만 유의미한 작업을 하지못할때 사용해서 다음 상태로 넘겨주는것을 의미한다. 바로한번 예시를 보자
public class YieldTest extends Thread {
private boolean key;
public void setKey(boolean key){
this.key=key;
}
@Override
public void run(){
while(true){
if(key){
System.out.println("유의미한 작업중!");
}
System.out.println("무의미한 작업중!");
}
}
}위 코드를 보면 key라는 boolean에의해 while안에서 유의미한 작업과 무의미한 작업이 이루어진다.
여기서 무의미하다는 것은 아무런 코드도 실행이 되니않는데 while문을 돌고있는 상황을 의미한다. 만약 이런 상황이라면 컴퓨터는 필요한 자원을 낭비하게 되고 다른 쓰레드를 실행해도 되는 상황에서 쓸대없이 시간을 낭비하는것과 같다.
이렇때 yiel;d가 필요하다.
public class YieldTest extends Thread {
private boolean key;
public void setKey(boolean key){
this.key=key;
}
@Override
public void run(){
while(true){
if(key){
System.out.println("유의미한 작업중!");
}
else{
yield();
}
System.out.println("무의미한 작업중!");
}
}
}
수정된 코드에는 if문에 else에 yield를 붙혔다. 이렇게 되면 key값이 false여서 무의미한 작업을 하는게 아니라 다른 쓰레드에세 현재 자신의 실행 시간을 넘겨주게 된다.
1-4 join
join은 yield와 비슷하게 다른 쓰레드에게 실행을 넘겨주지만 이번에는 직접 어떤 쓰레드에게 넘겨줄 것인지 정할 수 있다.
public class JoinTest extends Thread {
private Thread main;
private boolean key;
public void setMainThread(Thread main){
this.main=main;
}
public void setKey(boolean key){
this.key=key;
}
@Override
public void run(){
while(true){
if(key){
System.out.println("필요한 작업");
}
else{
try{
main.join();
}catch (InterruptedException e){
}
}
System.out.println("무의미한 작업");
}
}
}
yield와 비슷하지만 필요한 대상의 쓰레드에서 join을 호출한다 이러면 호출한 대상이 완료되기를 기다린다.
추가적으로 join안에 숫자랄 적어주면 해당 시간동안 실행한다.
2. 동기화
이번에는 쓰레드의 가장 중요한 부분인 동기화를 알아보자.
우선 쓰레드는 프로세스의 데이터, 코드, 등을 공유한다는것을 알고있다. 그런데 여기서 한가지 문제가 있다.
만약 여러 쓰레드가 한가지 자원에 동시에 접근하는 상황이 온다고 생각해보자.
그자원을 단순히 읽는것이 아니라 수정을 한다면 각 쓰레드들은 원하는 기대값을 얻지 못할 수 있다.
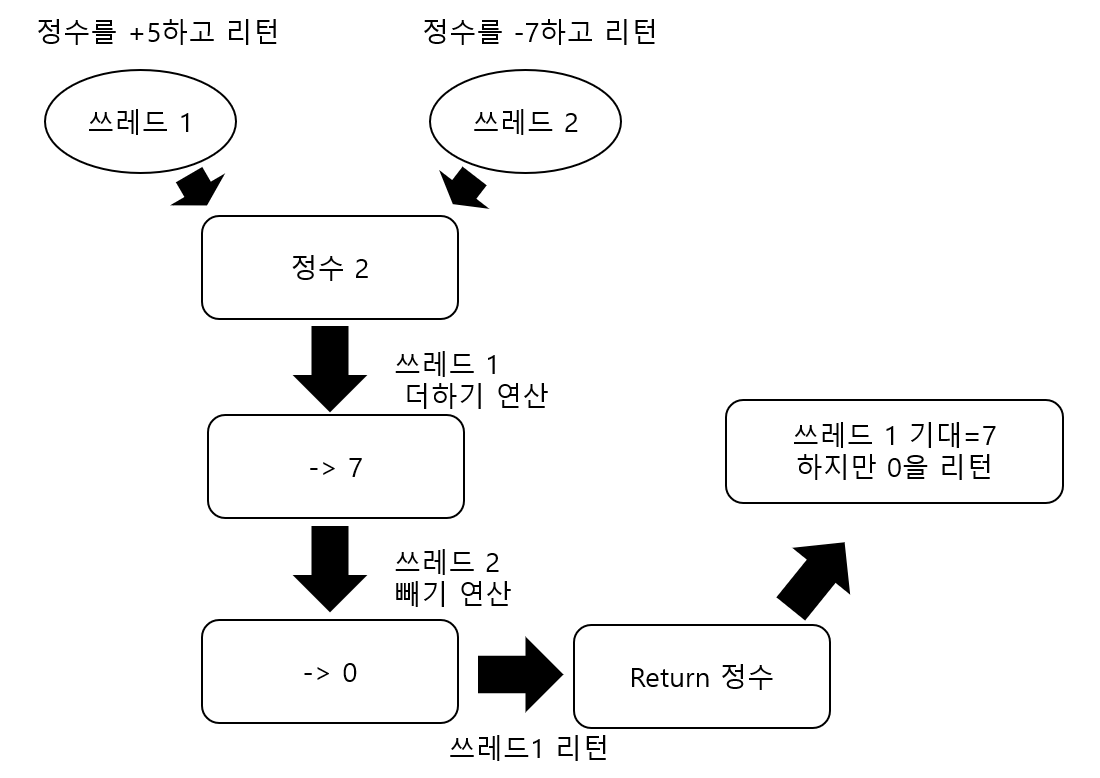
위 상황을 보면 동기화의 필요성을 느낄것이다.
그럼 자바에서 이런 상황을 어떤식으로 대처하는지 보자
synchronized
방법은 아주 간단하다. 동기화 시키고자하는 부분에 synchronized 키워드를 붙혀주면 된다.
public class SynchronizedSample {
//동기화 시킬 메소드
public synchronized void sample(){
}
public void sample2(){
//동기화 시킬 부분
synchronized (this){
}
}
}첫번째 방식은 메소드에 synchronized키워드를 붙이는것인데, 이렇게하면 이 메소드를 처음 실행시킨 쓰레드가 현재 메소드를 실행시킬 권한(lock)을 갖는다. 이러면 다른 쓰레드들은 저 권한이 없어서 실행을 시킬 수 없다.
그리고 lock을 가진 쓰레드가 메소드를 끝내면 lock을 반환한다.
다음으로는 코드의 일부를 synchronized를 붙이는것인데 메소드에 붙이는것과 마찬가지로 처음 저 부분까지 도착한 쓰레드가 소유권을 갖는다.
다만 2방식중 후자가 보다 좋은 방식이다. 이유는 쓰레드에서 lock을 가지지 못한 쓰레드는 무한정 대기해야 하기 때문에 메소드에서 동기화가 필요하지 않은 부분까지 묶을 이유가 없기 때문이다.
그럼 synchronized의 사용을 바로 한번 예시를 통해 보자
public class Coin {
private int money;
public void setMoney(int money){
this.money=money;
}
public int getMoney(){
return money;
}
}public class SynchronizedSample extends Thread{
private int value;
private Coin coin;
private String name;
public SynchronizedSample(String name){
this.name=name;
}
public void setCoin(Coin coin){
this.coin=coin;
}
public void setValue(int value){
this.value=value;
}
@Override
public void run(){
for(int i=0;i<300;i++){
coin.setMoney(coin.getMoney()+value);
System.out.println(name+": "+coin.getMoney());
}
System.out.println(name+"의 결과:"+coin.getMoney());
}
}public class Main {
public static void main(String[] args) {
SynchronizedSample sample1=new SynchronizedSample("t1");
SynchronizedSample sample2=new SynchronizedSample("t2");
Coin coin=new Coin();
coin.setMoney(1000);
sample1.setCoin(coin);
sample2.setCoin(coin);
sample1.setValue(1);
sample2.setValue(-1);
sample1.start();
sample2.start();
}
}
우선 위의 코드는 동기화를 하지않은 코드이다.
우선 SynchronizedSample은 value로 정한 정수를 coin에 300번 더하는 역할을 한다.
그리고 매인에서 보면 sample1은 value로 1을 sampl2는 value로 -1을 주었다.
그렇다면 우리는 1300,1000 이던, 1000,1000이 나오기를 기대할 것이다.
하지만 동기화를 해주지 않아서 위같이 랜덤한 결과가 나오고만다.
이럴 경우 동기화를 해주면 결과는 항상 1300,1000이거나 1000,1000이 나온다.
public class SynchronizedSample extends Thread{
private int value;
private Coin coin;
private String name;
public SynchronizedSample(String name){
this.name=name;
}
public void setCoin(Coin coin){
this.coin=coin;
}
public void setValue(int value){
this.value=value;
}
@Override
public void run(){
synchronized (this){
for(int i=0;i<300;i++){
coin.setMoney(coin.getMoney()+value);
}
}
System.out.println(name+"의 결과:"+coin.getMoney());
}
}
run부분을 동기화해줘서 결과를 기대한대로 만들수 있었다.
notify,notifyAlll,wait
쓰레드의 synchronized로인해 우리는 lock을 거는방법을 배웠다. 그런데 이 lock을 가지고 있는 쓰레드의 작업 시간이 많이 길어진다면 lock을 가지기위해 기다리는 다른 쓰레드는 대기시간이 늘어나서 프로그램의 효율이 떨어지게 된다.
그래서 쓰레드의 동기화에서 중요한 부분중 하나는 lock을 가진 상태에서 오래동안 머무르지 못하게 하는것이다.
일럴때 사용하는것이 nofify,notifyAll와 wait이다. wait는 자신이 가진 lock을 반환하고 대기를 한다. nofiry는 다른 쓰레드에게 대기중인 쓰레드들중 임의의 쓰레드에게 해당 lock을 반환한다 그리고 notifyAll은 해당 lock을 기다리는 모든 쓰레드에게 알린다.
3가지 모두 이번에는 Thread클래스에 구현된게 아니라 Object객체에 구현된 것이다.
각각의 사용방법은 간단하다. 우선 사용하기 위해서는 synchronized블록이 필요하다. synchronized블록 안에서 대기가 필요한 부분에 wait메소드를 호출하면 lock을 넘겨준다. 다음으로 notify,notifyAll은 다른 쓰레드가 작업을 실행해도 좋을때 호출을 해주면 된다.
public class Sample {
private boolean key;
private int value;
public void test(){
synchronized (this){
while(true){
if(key){
value++;
notify();
}
try{
wait();
}catch (InterruptedException e){}
}
}
}
}사용은 위와같다. 우선 key가 없다면 위에서는 while을 공회전하게 된다. 그럴때 wait를 통해서 lock을 반환해준다. 그리고 key를 얻으면 유의미한 동작을 한다음 다른곳에서 이 lock을 기다르는 쓰레드를 깨우는 notifty를 호출해주면 된다.
ReetrantLock,Condition
이번에는 synchronized와 비슷하지만 lock을 거는 부분과 푸는 부분을 명시할 수 있는 ReentrantLock을 보자.
ReentrantLock은 lock,unlock 메소드를 통해 locking이 필요한부분부터 locking을 끝내는 부분을 명시할 수 있다.
import java.util.concurrent.locks.ReentrantLock;
public class Coin {
private final ReentrantLock lock=new ReentrantLock();
private int money;
public void setMoney(int money){
this.money=money;
}
public int getMoney(){
return money;
}
public void compute(int value){
lock.lock();
try{
for(int i=0;i<10000;i++){
money+=value;
}
System.out.println(money);
}catch (Exception e){}
finally {
lock.unlock();
}
}
}
사용 방법은 위와같다.
compute메소드를 보면 lock을 걸지않으면 여러 쓰레드가 money변수를 동시게 건드려서 예상하지 못한 결과를 얻는다.
하지면 계산하지전에 lock메소드를 호출하여 locking을 시작했다.
그리고 try-catch-finally문을 통해 작업을 했는데 try-catch-finally문을 사용한 이유는 만약 작업도중 에러가 발생해서 lock을 놓지않으면 다른 대기중인 쓰레드들이 사용하지 못하기때문에 finally에 unlock메소드를 호출한 것이다.
그리고 또한 참고할것이 이 ReentrantLock에서는 wait,notiry,notifyAll을 사용할 수 없다. 대신에 Condition을 사용해서
await,signal,signalAll을 이용해야한다.
사용방법은 아래와 같다.
import java.util.concurrent.locks.Condition;
import java.util.concurrent.locks.ReentrantLock;
public class Coin {
private final ReentrantLock lock=new ReentrantLock();
private final Condition condition=lock.newCondition();
private int money;
public void setMoney(int money){
this.money=money;
}
public int getMoney(){
return money;
}
public void compute(int value){
lock.lock();
try{
for(int i=0;i<10000;i++){
money+=value;
}
condition.await();
condition.signal();
condition.signalAll();
System.out.println(money);
}catch (Exception e){}
finally {
lock.unlock();
}
}
}
Condition은 ReentrantLock을 통해 생성하고 Condition을 통해 await,signal,signalAll을 이용한다.
그런데 ReentrantLock과 synchronized가 비슷해보이는데 왜 따로 만들었는지 의문이 들 수 있는데 한가지 예제를 보면 차이점을 명확히 이해할 수 있다.
public void foo1(){
lock.lock();
}
public void foo2(){
lock.unlock();
}자 위 코드를 보자 lock을 거는 부분과 푸는 부분이 서로 다른 메소드에서 이뤄진다. 그런데 synchronized는 위같이 lock과 unlock을 따로 명시하지 못히기때문에 저렇게 나누는것이 불가능하다.
추가적으로 2가지 방식에서 퍼포먼스 측면에서도 ReentrantLock이 보다 낫다고 알려져있다.



